Spring Data JPA
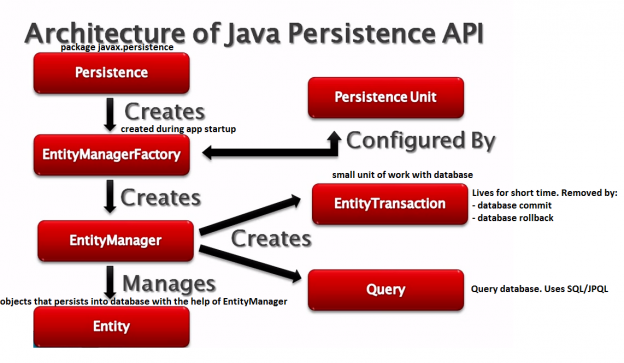
JPA
JPA(Java Persistence API)意即 Java 持久化 API,是 Sun 官方在 JDK5.0 后提出的 Java 持久化规范(JSR 338,这些接口所在包为javax.persistence,详细内容可参考https://github.com/javaee/jpa-spec)
JPA 的出现主要是为了简化持久层开发以及整合ORM技术,结束 Hibernate,TopLink,JDO等ORM框架各自为营的局面。JPA是在吸收现有ORM框架的基础上发展而来,易于使用,伸缩性强。总的来说,JPA 包括以下 3 方面的技术:
- ORM 映射元数据: 支持 XML 和注解两种元数据的形式,元数据描述对象和表之间的映射关系
- API: 操作实体对象来执行 CRUD 操作
- 查询语言: 通过面向对象而非面向数据库的查询语言(JPQL)查询数据,避免程序的 SQL 语句紧密耦合
Spring Data Jpa
Spring 官方的解释https://spring.io/projects/spring-data-jpa#overview
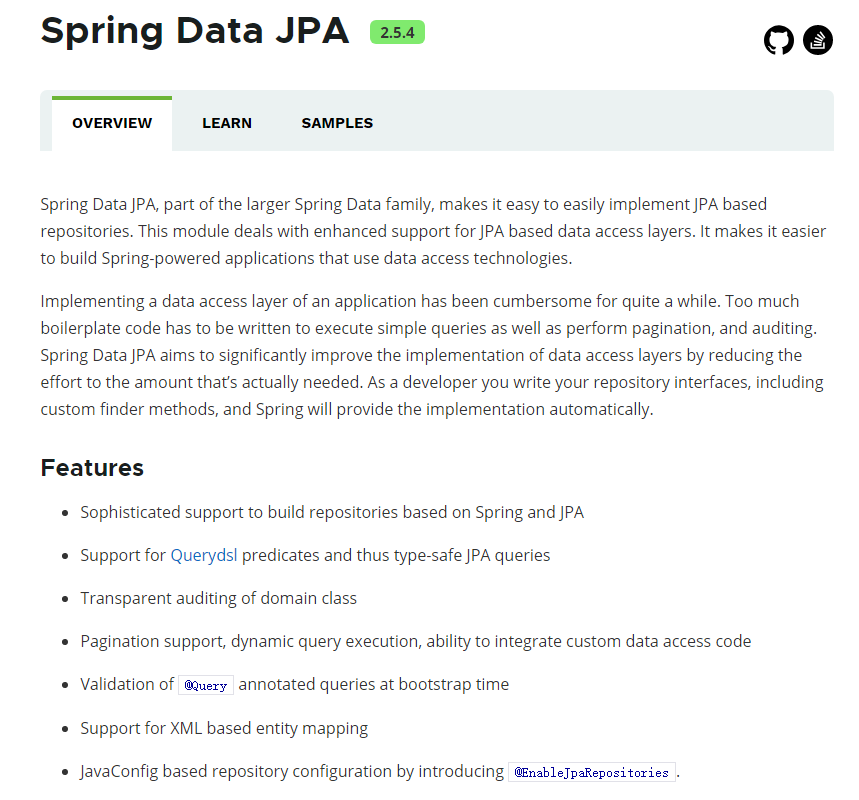
Spring Data JPA 是 Spring Data 家族的一部分,可以轻松实现基于 JPA 的存储库。 此模块处理对基于 JPA 的数据访问层的增强支持。 它使构建使用数据访问技术的 Spring 驱动应用程序变得更加容易。
在相当长的一段时间内,实现应用程序的数据访问层一直很麻烦。 必须编写太多样板代码来执行简单查询以及执行分页和审计。 Spring Data JPA 旨在通过减少实际需要的工作量来显著改善数据访问层的实现。 作为开发人员,您编写 repository 接口,包括自定义查找器方法,Spring 将自动提供实现。
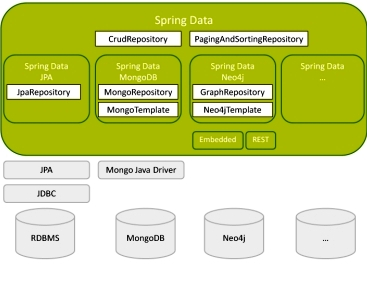
Jpa,Hibernate,Spring Data Jpa 三者之间的关系
总的来说JPA是ORM规范,Hibernate,TopLink 等是 JPA 规范的具体实现,这样的好处是开发者可以面向 JPA 规范进行持久层的开发,而底层的实现则是可以切换的。Spring Data Jpa 则是在 JPA 之上添加另一层抽象(Repository层的实现),极大地简化持久层开发及 ORM 框架切换的成本。
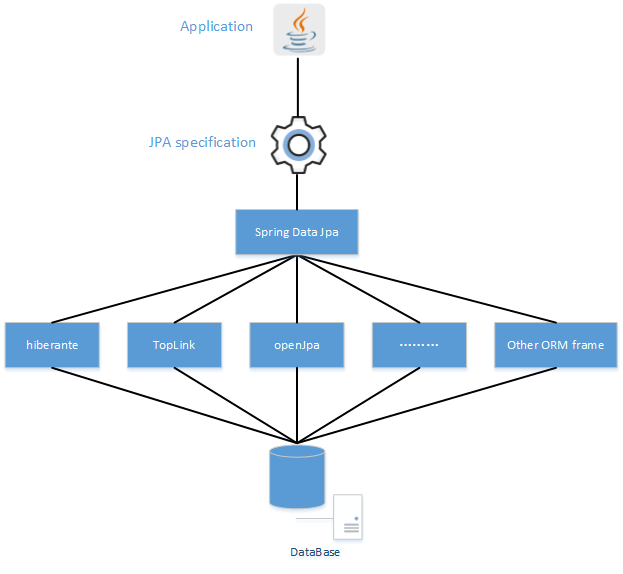
Spring Data Jpa 的 java 配置方案
在 Spring Boot 没出来之前如果要采用 Java Configuration 来配置 Spring Data Jpa 你需要配置如下的 Bean
参考自 Spring In Action 及Spring Data Jpa 官方文档 5.1.2. Annotation-based Configuration
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import javax.persistence.EntityManagerFactory;
import javax.sql.DataSource;
/**
* 注意:spring-data-jpa2.x版本需要spring版本为5.x
* 否则会报Initialization of bean failed; nested exception is java.lang.AbstractMethodError错误
* 参考:https://stackoverflow.com/questions/47558017/error-starting-a-spring-application-initialization-of-bean-failed-nested-excep
* 搭配方案:spring4+spring-data-jpa1.x或spring5+spring-data-jpa2.x
*/
@Configuration
// 借助spring data实现自动化的jpa repository,只需编写接口无需编写实现类
// 相当于xml配置的<jpa:repositories base-package="com.example.repository" />
// repositoryImplementationPostfix默认就是Impl
// entityManagerFactoryRef默认就是entityManagerFactory
// transactionManagerRef默认就是transactionManager
@EnableJpaRepositories(basePackages = {"com.example.repository"},
repositoryImplementationPostfix = "Impl",
entityManagerFactoryRef = "entityManagerFactory",
transactionManagerRef = "transactionManager")
@EnableTransactionManagement // 启用事务管理器
public class SpringDataJpaConfig {
// 配置jpa厂商适配器(参见spring实战p320)
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter jpaVendorAdapter = new HibernateJpaVendorAdapter();
// 设置数据库类型(可使用org.springframework.orm.jpa.vendor包下的Database枚举类)
jpaVendorAdapter.setDatabase(Database.MYSQL);
// 设置打印sql语句
jpaVendorAdapter.setShowSql(true);
// 设置不生成ddl语句
jpaVendorAdapter.setGenerateDdl(false);
// 设置hibernate方言
jpaVendorAdapter.setDatabasePlatform("org.hibernate.dialect.MySQL5Dialect");
return jpaVendorAdapter;
}
// 配置实体管理器工厂
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory(
DataSource dataSource, JpaVendorAdapter jpaVendorAdapter) {
LocalContainerEntityManagerFactoryBean emfb = new LocalContainerEntityManagerFactoryBean();
// 注入数据源
emfb.setDataSource(dataSource);
// 注入jpa厂商适配器
emfb.setJpaVendorAdapter(jpaVendorAdapter);
// 设置扫描基本包
emfb.setPackagesToScan("com.example.entity");
return emfb;
}
// 配置jpa事务管理器
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory emf) {
JpaTransactionManager transactionManager = new JpaTransactionManager();
// 配置实体管理器工厂
transactionManager.setEntityManagerFactory(emf);
return transactionManager;
}
}
启用 web 支持还需要在 Spring MVC 配置类上添加 @EnableSpringDataWebSupport 注解
@Configuration
@ComponentScan(basePackages = {"cn.fulgens.controller"})
@EnableWebMvc // 启用spring mvc
@EnableSpringDataWebSupport // 启用springmvc对spring data的支持
public class WebMvcConfig extends WebMvcConfigurerAdapter {
}
Spring Boot 整合 Spring Data Jpa
导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
相关配置
server:
port: 8080
servlet:
context-path: /
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&useSSL=false
username: root
password: mysql123
jpa:
database: MySQL
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect
show-sql: true
hibernate:
ddl-auto: update
ddl-auto
- create:每次运行程序时,都会重新创建表,故而数据会丢失
- create-drop:每次运行程序时会先创建表结构,然后待程序结束时清空表
- upadte:每次运行程序,没有表时会创建表,如果对象发生改变会更新表结构,原有数据不会清空,只会更新(推荐使用)
- validate:运行程序会校验数据与数据库的字段类型是否相同,字段不同会报错
- none: 禁用 DDL 处理
Spring Data Jpa 的使用
Spring Data Jpa UML 类图
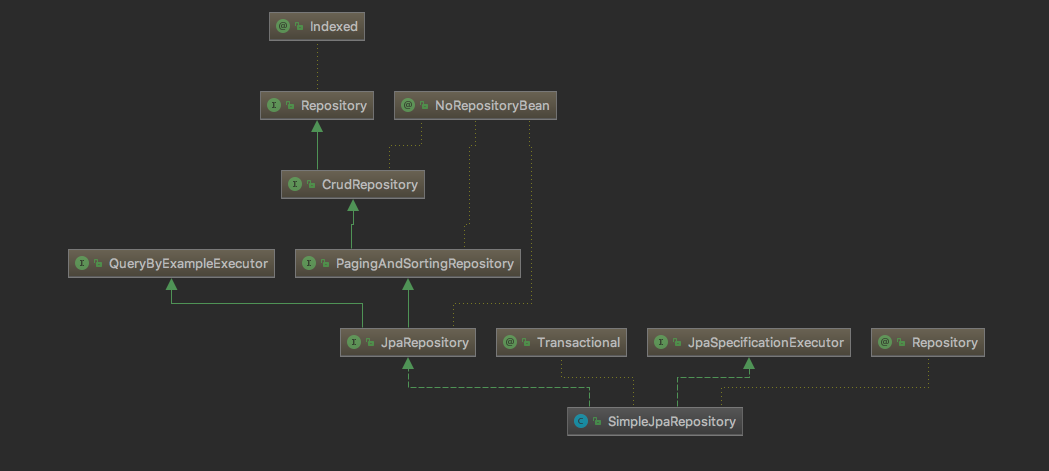
简单的 REST CRUD 示例
实体类
/src/main/java/com/example/springbootjpa/entity/User
package com.example.springbootjpa.entity;
import lombok.Data;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
@Entity
@Table(name = "tb_user")
@Data
public class User {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "username", unique = true, nullable = false, length = 64)
private String username;
@Column(name = "password", nullable = false, length = 64)
private String password;
@Column(name = "email", length = 64)
private String email;
}
主键采用 UUID 策略
@GenericGenerator 是 Hibernate 提供的主键生成策略注解,注意下面的 @GeneratedValue(JPA 注解)使用generator = "idGenerator"引用了上面的name = "idGenerator"主键生成策略
一般简单的 Demo 示例中只会使用@GeneratedValue(strategy = GenerationType.IDENTITY)这种主键自增的策略,而实际数据库中表字段主键类型很少是int型的
JPA 自带的几种主键生成策略
- TABLE: 使用一个特定的数据库表格来保存主键
- SEQUENCE: 根据底层数据库的序列来生成主键,条件是数据库支持序列。这个值要与 generator 一起使用,generator 指定生成主键使用的生成器(可能是 orcale 中自己编写的序列)
- IDENTITY: 主键由数据库自动生成(主要是支持自动增长的数据库,如 mysql)
- AUTO: 主键由程序控制,也是 GenerationType 的默认值
Dao 层
/src/main/java/com/example/springbootjpa/repository/UserRepository
package com.example.springbootjpa.repository;
import com.example.springbootjpa.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, String> {
}
Controller 层
这里简单起见省略 Service 层
/src/main/java/com/example/springbootjpa/controller/UserController
package com.example.springbootjpa.controller;
import com.example.springbootjpa.entity.User;
import com.example.springbootjpa.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.web.bind.annotation.*;
import java.util.HashMap;
import java.util.Optional;
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping()
public User saveUser(@RequestBody User user) {
return userRepository.save(user);
}
@DeleteMapping("/{id}")
public void deleteUser(@PathVariable("id") String userId) {
userRepository.deleteById(userId);
}
@PutMapping("/{id}")
public User updateUser(@PathVariable("id") String userId, @RequestBody User user) {
user.setId(userId);
return userRepository.saveAndFlush(user);
}
@GetMapping("/{id}")
public User getUserInfo(@PathVariable("id") String userId) {
Optional<User> optional = userRepository.findById(userId);
return optional.orElseGet(User::new);
}
@GetMapping("/list")
public Page<User> pageQuery(@RequestParam(value = "pageNum", defaultValue = "1") Integer pageNum,
@RequestParam(value = "pageSize", defaultValue = "10") Integer pageSize) {
return userRepository.findAll(PageRequest.of(pageNum - 1, pageSize));
}
}
Spring Data Jpa 使用详解
Spring Data 查询方法
使用 Spring Data 创建查询只需四步:
- 声明一个接口继承自 Repository 或 Repositoy 的一个子接口,对于 Spring Data Jpa 通常是 JpaRepository,如:
interface PersonRepository extends Repository<Person, Long> { … }
- 在接口中声明查询方法,如:
interface PersonRepository extends Repository<Person, Long> {
List<Person> findByLastname(String lastname);
}
- 使用 JavaConfig 或 XML configuration配置 Spring,让 Spring 为声明的接口创建代理对象
3.1 JavaConfig 参见上文
3.2 使用 Xml 配置,可以像下面这样使用 jpa 命名空间进行配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<jpa:repositories base-package="com.acme.repositories"/>
</beans>
对于不同的
Spring Data子项目 Spring 提供了不同的 xml 命名空间,如对于Spring Data MongoDB可以将上面的 jpa 改为 mongodb。当然,使用Spring Boot这一步基本可以省略,我们需要做的就是在application.properties或application.yml文件中配置几个属性即可
- 注入 Repository 实例并使用,如:
class SomeClient {
private final PersonRepository repository;
SomeClient(PersonRepository repository) {
this.repository = repository;
}
void doSomething() {
List<Person> persons = repository.findByLastname("Matthews");
}
}
定义 Repository 接口
选择性暴露 CRUD 方法
一种方法是定义一个BaseRepository接口继承Repository接口,并从CrudRepository中 copy 你想暴露的 CRUD 方法
src/main/java/com/example/springbootjpa/repository/MyBaseRepository
package com.example.springbootjpa.repository;
import org.springframework.data.repository.NoRepositoryBean;
import org.springframework.data.repository.Repository;
import java.util.Optional;
/**
* 自定义Repository,选择性暴露CRUD方法
* @param <T>
* @param <ID>
*/
@NoRepositoryBean
public interface MyBaseRepository<T, ID> extends Repository<T, ID> {
Optional<T> findById(ID id);
<S extends T> S save(S entity);
}
注意:
MyBaseRepository上面加了@NoRepositoryBean注解
src/main/java/com/example/springbootjpa/repository/UserRepository2
package com.example.springbootjpa.repository;
import com.example.springbootjpa.entity.User;
import org.springframework.stereotype.Repository;
public interface UserRepository2 extends MyBaseRepository<User, String> {
}
Repository 方法的 Null 值处理
从 Spring Data2.0 开始对于返回单个聚合实例的 CRUD 方法可以使用 java8 Optional 接口作为方法返回值来表明可能存在的缺省值,典型示例为 CrudRepository 的 findById 方法
另外 Spring 也提供了几个注解来处理 Null 值
- @NonNullApi: 在包级别使用来声明参数和返回值不能为 Null
- @NonNull: 在参数或返回值上使用,当它们不能为 Null 时(如果在包级别上使用了@NonNullApi 注解则没有必要再使用@NonNull 注解了)
- @Nullable: 在参数或返回值上使用,当它们可以为 Null 时
查询方法
查询创建 Query Creation
Spring Data Jpa 通过解析方法名创建查询,框架在进行方法名解析时,会先把方法名多余的前缀find…By, read…By, query…By, count…By以及 get…By 截取掉,然后对剩下部分进行解析,第一个 By 会被用作分隔符来指示实际查询条件的开始。 我们可以在实体属性上定义条件,并将它们与 And 和 Or 连接起来,从而创建大量查询:
User findByUsername(String username);
List<User> findByUsernameIgnoreCase(String username);
List<User> findByUsernameLike(String username);
User findByUsernameAndPassword(String username, String password);
User findByEmail(String email);
List<User> findByEmailLike(String email);
List<User> findByIdIn(List<String> ids);
List<User> findByIdInOrderByUsername(List<String> ids);
void deleteByIdIn(List<String> ids);
Long countByUsernameLike(String username);
支持的关键字,示例及 JPQL 片段如下表所示:
| Keyword | Sample | JPQL snippet |
| ------- | ------ | ------------ ||
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith |… where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection<Age> ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection<Age> ages) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
具体 Spring Data Jpa 对方法名的解析规则可参看官方文档
限制查询结果
Spring Data Jpa 支持使用first,top 以及 Distinct 关键字来限制查询结果,如:
User findFirstByUsernameOrderByUsernameAsc(String username);
List<User> findTop10ByUsername(String username, Sort sort);
List<User> findTop10ByUsername(String username, Pageable pageable);
自定义查询 Using @Query
@Query 注解的使用非常简单,只需在声明的方法上面标注该注解,同时提供一个 JPQL 查询语句即可
@Query("select u from User u where u.email = ?1")
User getByEmail(String eamil);
@Query("select u from User u where u.username = ?1 and u.password = ?2")
User getByUsernameAndPassword(String username, String password);
@Query("select u from User u where u.username like %?1%")
List<User> getByUsernameLike(String username);
使用命名参数 Using Named Parameters
默认情况下,Spring Data JPA 使用基于位置的参数绑定,如前面所有示例中所述。 这使得查询方法在重构参数位置时容易出错。 要解决此问题,可以使用 @Param 注解为方法参数指定具体名称并在查询中绑定名称,如以下示例所示:
@Query("select u from User u where u.id = :id")
User getById(@Param("id") String userId);
@Query("select u from User u where u.username = :username or u.email = :email")
User getByUsernameOrEmail(@Param("username") String username, @Param("email") String email);
Using SpEL Expressions
从 Spring Data JPA release 1.4 开始,Spring Data JPA 支持名为 entityName 的变量。 它的用法是select x from #{#entityName} x。
entityName的解析方式如下:如果实体类在 @Entity 注解上设置了name属性,则使用它。否则,使用实体类的简单类名。为避免在 @Query 注解使用实际的实体类名,就可以使用#{#entityName}进行代替。如以上示例中,@Query注解的查询字符串里的 User 都可替换为#{#entityName}
@Query("select u from #{#entityName} u where u.email = ?1")
User getByEmail(String eamil);
原生查询 Native Queries
@Query 注解还支持通过将 nativeQuery 标志设置为true来执行原生查询,同样支持基于位置的参数绑定及命名参数,如:
@Query(value = "select * from tb_user u where u.email = ?1", nativeQuery = true)
User queryByEmail(String email);
@Query(value = "select * from tb_user u where u.email = :email", nativeQuery = true)
User queryByEmail(@Param("email") String email);
注意:Spring Data Jpa目前不支持对原生查询进行动态排序,但可以通过自己指定计数查询countQuery来使用原生查询进行分页,排序,如:
@Query(value = "select * from tb_user u where u.username like %?1%",
countQuery = "select count(1) from tb_user u where u.username = %?1%",
nativeQuery = true)
Page<User> queryByUsernameLike(String username, Pageable pageable);
分页查询及排序
Spring Data Jpa 可以在方法参数中直接传入Pageable 或 Sort 来完成动态分页或排序,通常 Pageable 或 Sort 会是方法的最后一个参数,如:
@Query("select u from User u where u.username like %?1%")
Page<User> findByUsernameLike(String username, Pageable pageable);
@Query("select u from User u where u.username like %?1%")
List<User> findByUsernameAndSort(String username, Sort sort);
那调用repository方法时传入什么参数呢?
对于 Pageable 参数,在 Spring Data 2.0 之前我们可以 new 一个org.springframework.data.domain.PageRequest对象,现在这些构造方法已经废弃,取而代之 Spring 推荐我们使用 PageRequest 的 of 方法
new PageRequest(0, 5);
new PageRequest(0, 5, Sort.Direction.ASC, "username");
new PageRequest(0, 5, new Sort(Sort.Direction.ASC, "username"));
PageRequest.of(0, 5);
PageRequest.of(0, 5, Sort.Direction.ASC, "username");
PageRequest.of(0, 5, Sort.by(Sort.Direction.ASC, "username"));
注意:
Spring Data PageRequest的page参数是从0开始的 zero-based page index
对于Sort参数,同样可以 new 一个org.springframework.data.domain.Sort,但推荐使用Sort.by方法
自定义修改,删除 Modifying Queries
单独使用 @Query 注解只是查询,如涉及到修改,删除则需要再加上 @Modifying 注解,如:
@Transactional()
@Modifying
@Query("update User u set u.password = ?2 where u.username = ?1")
int updatePasswordByUsername(String username, String password);
@Transactional()
@Modifying
@Query("delete from User where username = ?1")
void deleteByUsername(String username);
注意:Modifying queries can only use void or int/Integer as return type!
多表查询
这里使用级联查询进行多表的关联查询
多对多
/src/main/java/com/example/springbootjpa/entity/User
package com.example.springbootjpa.entity;
import lombok.Data;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
import java.util.Date;
import java.util.Set;
import java.util.UUID;
@Entity
@Table(name = "tb_user")
@Data
public class User {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "username", unique = true, nullable = false, length = 64)
private String username;
@Column(name = "password", nullable = false, length = 64)
private String password;
@Column(name = "email", unique = true, length = 64)
private String email;
@ManyToMany(targetEntity = Role.class, cascade = {CascadeType.PERSIST, CascadeType.MERGE}, fetch = FetchType.LAZY)
@JoinTable(name = "tb_user_role", joinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")},
inverseJoinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")})
private Set<Role> roles;
}
/src/main/java/com/example/springbootjpa/entity/Role
package com.example.springbootjpa.entity;
import lombok.Data;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
@Entity
@Table(name = "tb_role")
@Data
public class Role {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "role_name", unique = true, nullable = false, length = 64)
private String roleName;
}
测试
@Test
public void findByIdTest() {
Optional<User> optional = userRepository.findById("40289f0c65674a930165674d54940000");
Set<Role> roles = optional.get().getRoles();
System.out.println(optional.get());
}
不出意外会报 Hibernate 懒加载异常,无法初始化代理类,No Session:
org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: com.example.springbootjpa.entity.User.roles, could not initialize proxy - no Session
原因:Spring Boot 整合 JPA 后 Hibernate 的 Session 就交付给 Spring 去管理。每次数据库操作后,会关闭Session,当我们想要用懒加载方式去获得数据的时候,原来的Session已经关闭,不能获取数据,所以会抛出这样的异常。
解决方法:
在application.yml中做如下配置:
spring:
jpa:
open-in-view: true
properties:
hibernate:
enable_lazy_load_no_trans: true
一对多(多对一)
/src/main/java/com/example/springbootjpa/entity/Department
package com.example.springbootjpa.entity;
import lombok.Data;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
import java.util.Set;
@Entity
@Table(name = "tb_dept")
@Data
public class Department {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "dept_name", unique = true, nullable = false, length = 64)
private String deptName;
@OneToMany(mappedBy = "department", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Set<Employee> employees;
}
/src/main/java/com/example/springbootjpa/entity/Employee
package com.example.springbootjpa.entity;
import lombok.Data;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
import java.util.UUID;
@Entity
@Table(name = "tb_emp")
@Data
public class Employee {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "emp_name", nullable = false, length = 64)
private String empName;
@Column(name = "emp_job", length = 64)
private String empJob;
@Column(name = "dept_id", insertable = false, updatable = false)
private String deptId;
@ManyToOne(targetEntity = Department.class, cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinColumn(name = "dept_id")
private Department department;
}
测试
@Test
public void findByIdTest() {
Optional<Employee> optional = employeeRepository.findById("93fce66c1ef340fa866d5bd389de3d79");
System.out.println(optional.get());
}
结果报错了...
java.lang.StackOverflowError
at java.base/java.lang.Exception.<init>(Exception.java:102)
at java.base/java.lang.ReflectiveOperationException.<init>(ReflectiveOperationException.java:89)
at java.base/java.lang.reflect.InvocationTargetException.<init>(InvocationTargetException.java:73)
at jdk.internal.reflect.GeneratedConstructorAccessor54.newInstance(Unknown Source)
at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.base/java.lang.reflect.Constructor.newInstance(Constructor.java:488)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:425)
at com.mysql.jdbc.PreparedStatement.getInstance(PreparedStatement.java:761)
at com.mysql.jdbc.ConnectionImpl.clientPrepareStatement(ConnectionImpl.java:1404)
at com.mysql.jdbc.ConnectionImpl.prepareStatement(ConnectionImpl.java:4121)
at com.mysql.jdbc.ConnectionImpl.prepareStatement(ConnectionImpl.java:4025)
at com.zaxxer.hikari.pool.ProxyConnection.prepareStatement(ProxyConnection.java:318)
at com.zaxxer.hikari.pool.HikariProxyConnection.prepareStatement(HikariProxyConnection.java)
at org.hibernate.engine.jdbc.internal.StatementPreparerImpl$5.doPrepare(StatementPreparerImpl.java:145)
at org.hibernate.engine.jdbc.internal.StatementPreparerImpl$StatementPreparationTemplate.prepareStatement(StatementPreparerImpl.java:171)
at org.hibernate.engine.jdbc.internal.StatementPreparerImpl.prepareQueryStatement(StatementPreparerImpl.java:147)
at org.hibernate.loader.plan.exec.internal.AbstractLoadPlanBasedLoader.prepareQueryStatement(AbstractLoadPlanBasedLoader.java:226)
at org.hibernate.loader.plan.exec.internal.AbstractLoadPlanBasedLoader.executeQueryStatement(AbstractLoadPlanBasedLoader.java:190)
at org.hibernate.loader.plan.exec.internal.AbstractLoadPlanBasedLoader.executeLoad(AbstractLoadPlanBasedLoader.java:121)
at org.hibernate.loader.plan.exec.internal.AbstractLoadPlanBasedLoader.executeLoad(AbstractLoadPlanBasedLoader.java:86)
at org.hibernate.loader.collection.plan.AbstractLoadPlanBasedCollectionInitializer.initialize(AbstractLoadPlanBasedCollectionInitializer.java:87)
at org.hibernate.persister.collection.AbstractCollectionPersister.initialize(AbstractCollectionPersister.java:688)
at org.hibernate.event.internal.DefaultInitializeCollectionEventListener.onInitializeCollection(DefaultInitializeCollectionEventListener.java:75)
at org.hibernate.internal.SessionImpl.initializeCollection(SessionImpl.java:2223)
at org.hibernate.collection.internal.AbstractPersistentCollection$4.doWork(AbstractPersistentCollection.java:565)
at org.hibernate.collection.internal.AbstractPersistentCollection.withTemporarySessionIfNeeded(AbstractPersistentCollection.java:247)
at org.hibernate.collection.internal.AbstractPersistentCollection.initialize(AbstractPersistentCollection.java:561)
at org.hibernate.collection.internal.AbstractPersistentCollection.read(AbstractPersistentCollection.java:132)
at org.hibernate.collection.internal.PersistentSet.hashCode(PersistentSet.java:430)
at com.example.springbootjpa.entity.Department.hashCode(Department.java:14)
通过日志看 sql 的输出,发现了 sql 重复执行了好多次。以下我截取了前 10 条 sql 记录。
Hibernate: select employee0_.id as id1_1_0_, employee0_.dept_id as dept_id2_1_0_, employee0_.emp_job as emp_job3_1_0_, employee0_.emp_name as emp_name4_1_0_ from tb_emp employee0_ where employee0_.id=?
Hibernate: select department0_.id as id1_0_0_, department0_.dept_name as dept_nam2_0_0_ from tb_dept department0_ where department0_.id=?
Hibernate: select employees0_.dept_id as dept_id2_1_0_, employees0_.id as id1_1_0_, employees0_.id as id1_1_1_, employees0_.dept_id as dept_id2_1_1_, employees0_.emp_job as emp_job3_1_1_, employees0_.emp_name as emp_name4_1_1_ from tb_emp employees0_ where employees0_.dept_id=?
Hibernate: select department0_.id as id1_0_0_, department0_.dept_name as dept_nam2_0_0_ from tb_dept department0_ where department0_.id=?
Hibernate: select employees0_.dept_id as dept_id2_1_0_, employees0_.id as id1_1_0_, employees0_.id as id1_1_1_, employees0_.dept_id as dept_id2_1_1_, employees0_.emp_job as emp_job3_1_1_, employees0_.emp_name as emp_name4_1_1_ from tb_emp employees0_ where employees0_.dept_id=?
Hibernate: select employees0_.dept_id as dept_id2_1_0_, employees0_.id as id1_1_0_, employees0_.id as id1_1_1_, employees0_.dept_id as dept_id2_1_1_, employees0_.emp_job as emp_job3_1_1_, employees0_.emp_name as emp_name4_1_1_ from tb_emp employees0_ where employees0_.dept_id=?
Hibernate: select employees0_.dept_id as dept_id2_1_0_, employees0_.id as id1_1_0_, employees0_.id as id1_1_1_, employees0_.dept_id as dept_id2_1_1_, employees0_.emp_job as emp_job3_1_1_, employees0_.emp_name as emp_name4_1_1_ from tb_emp employees0_ where employees0_.dept_id=?
Hibernate: select employees0_.dept_id as dept_id2_1_0_, employees0_.id as id1_1_0_, employees0_.id as id1_1_1_, employees0_.dept_id as dept_id2_1_1_, employees0_.emp_job as emp_job3_1_1_, employees0_.emp_name as emp_name4_1_1_ from tb_emp employees0_ where employees0_.dept_id=?
Hibernate: select employees0_.dept_id as dept_id2_1_0_, employees0_.id as id1_1_0_, employees0_.id as id1_1_1_, employees0_.dept_id as dept_id2_1_1_, employees0_.emp_job as emp_job3_1_1_, employees0_.emp_name as emp_name4_1_1_ from tb_emp employees0_ where employees0_.dept_id=?
Hibernate: select employees0_.dept_id as dept_id2_1_0_, employees0_.id as id1_1_0_, employees0_.id as id1_1_1_, employees0_.dept_id as dept_id2_1_1_, employees0_.emp_job as emp_job3_1_1_, employees0_.emp_name as emp_name4_1_1_ from tb_emp employees0_ where employees0_.dept_id=?
通过观察发现,第一条 sql 是执行查询 Employee 的 sql,第二条 sql 是执行查询 Department 的 sql,第三条 sql 是执行 Department 里面所有员工的 sql,第四条 sql 是执行查询 Department 的 sql,后面所有的 sql 都是执行查询 Department 里面所有员工的 sql。
很明显发生了循环依赖的情况。这是Lombok的@Data注解的锅。Lombok的@Data注解相当于@Getter,@Setter,@RequiredArgsConstructor,@ToString,@EqualsAndHashCode这几个注解。
我们可以通过反编译看一下Lombok生成的toString()方法
// Employee
public String toString() {
return "Employee(id=" + getId() + ", empName=" + getEmpName() + ", empJob=" + getEmpJob() + ", deptId=" + getDeptId() + ", department=" + getDepartment() + ")";
}
// Department
public String toString() {
return "Department(id=" + getId() + ", deptName=" + getDeptName() + ", employees=" + getEmployees() + ")";
}
可以发现Lombok为我们生成的toString()方法覆盖了整个类的所有属性
现在将 @Data 注解去掉,替换为 @Setter,@Getter,@EqualsAndHashCode,重写 toString() 方法
// Department
@Override
public String toString() {
return "Department{" +
"id='" + id + '\'' +
", deptName='" + deptName + '\'' +
'}';
}
// Employee
@Override
public String toString() {
return "Employee{" +
"id='" + id + '\'' +
", empName='" + empName + '\'' +
", empJob='" + empJob + '\'' +
", deptId='" + deptId + '\'' +
", department=" + department +
'}';
}
再次运行测试用例,测试通过,以上 Employee toString()方法打印的 department 会触发懒加载,最终日志输出的 sql 如下:
Hibernate: select employee0_.id as id1_1_0_, employee0_.dept_id as dept_id2_1_0_, employee0_.emp_job as emp_job3_1_0_, employee0_.emp_name as emp_name4_1_0_ from tb_emp employee0_ where employee0_.id=?
Hibernate: select department0_.id as id1_0_0_, department0_.dept_name as dept_nam2_0_0_ from tb_dept department0_ where department0_.id=?
Employee{id='93fce66c1ef340fa866d5bd389de3d79', empName='jack', empJob='hr', deptId='0a4fe7234fff42afad34f6a06a8e1821', department=Department{id='0a4fe7234fff42afad34f6a06a8e1821', deptName='人事部'}}
再来测试查询 Department
@Test
public void findByIdTest() {
Optional<Department> optional = departmentRepository.findById("0a4fe7234fff42afad34f6a06a8e1821");
Set<Employee> employees = optional.get().getEmployees();
Assert.assertNotEquals(0, employees.size());
}
同样还是报了堆栈溢出,错误定位在 Department 和 Employee 的 hashCode()方法上
java.lang.StackOverflowError
at com.mysql.jdbc.Util.handleNewInstance(Util.java:439)
at com.mysql.jdbc.ResultSetImpl.getInstance(ResultSetImpl.java:342)
at com.mysql.jdbc.MysqlIO.buildResultSetWithRows(MysqlIO.java:3132)
at com.mysql.jdbc.MysqlIO.getResultSet(MysqlIO.java:477)
at com.mysql.jdbc.MysqlIO.readResultsForQueryOrUpdate(MysqlIO.java:3115)
at com.mysql.jdbc.MysqlIO.readAllResults(MysqlIO.java:2344)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2739)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2486)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1858)
at com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:1966)
at com.zaxxer.hikari.pool.ProxyPreparedStatement.executeQuery(ProxyPreparedStatement.java:52)
at com.zaxxer.hikari.pool.HikariProxyPreparedStatement.executeQuery(HikariProxyPreparedStatement.java)
at org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:60)
at org.hibernate.loader.plan.exec.internal.AbstractLoadPlanBasedLoader.getResultSet(AbstractLoadPlanBasedLoader.java:419)
at org.hibernate.loader.plan.exec.internal.AbstractLoadPlanBasedLoader.executeQueryStatement(AbstractLoadPlanBasedLoader.java:191)
at org.hibernate.loader.plan.exec.internal.AbstractLoadPlanBasedLoader.executeLoad(AbstractLoadPlanBasedLoader.java:121)
at org.hibernate.loader.plan.exec.internal.AbstractLoadPlanBasedLoader.executeLoad(AbstractLoadPlanBasedLoader.java:86)
at org.hibernate.loader.collection.plan.AbstractLoadPlanBasedCollectionInitializer.initialize(AbstractLoadPlanBasedCollectionInitializer.java:87)
at org.hibernate.persister.collection.AbstractCollectionPersister.initialize(AbstractCollectionPersister.java:688)
at org.hibernate.event.internal.DefaultInitializeCollectionEventListener.onInitializeCollection(DefaultInitializeCollectionEventListener.java:75)
at org.hibernate.internal.SessionImpl.initializeCollection(SessionImpl.java:2223)
at org.hibernate.collection.internal.AbstractPersistentCollection$4.doWork(AbstractPersistentCollection.java:565)
at org.hibernate.collection.internal.AbstractPersistentCollection.withTemporarySessionIfNeeded(AbstractPersistentCollection.java:247)
at org.hibernate.collection.internal.AbstractPersistentCollection.initialize(AbstractPersistentCollection.java:561)
at org.hibernate.collection.internal.AbstractPersistentCollection.read(AbstractPersistentCollection.java:132)
at org.hibernate.collection.internal.PersistentSet.hashCode(PersistentSet.java:430)
at com.example.springbootjpa.entity.Department.hashCode(Department.java:17)
依旧是Lombok的锅,@EqualsAndHashCode为我们生成的equals()和hashCode()方法会使用所有属性,注意,Department中employees是Set 集合,当我们调用department.getEmployees()时,Employee的hashCode()方法会被调用,Employee中的hashCode()又依赖于Department的HashCode()方法,这样又形成了循环引用...
// Department
public int hashCode() {
int i = 43;
String $id = getId();
int result = ($id == null ? 43 : $id.hashCode()) + 59;
String $deptName = getDeptName();
result = (result * 59) + ($deptName == null ? 43 : $deptName.hashCode());
Set $employees = getEmployees();
int i2 = result * 59;
if ($employees != null) {
i = $employees.hashCode();
}
return i2 + i;
}
// Employee
public int hashCode() {
int i = 43;
String $id = getId();
int result = ($id == null ? 43 : $id.hashCode()) + 59;
String $empName = getEmpName();
result = (result * 59) + ($empName == null ? 43 : $empName.hashCode());
String $empJob = getEmpJob();
result = (result * 59) + ($empJob == null ? 43 : $empJob.hashCode());
String $deptId = getDeptId();
result = (result * 59) + ($deptId == null ? 43 : $deptId.hashCode());
Department $department = getDepartment();
int i2 = result * 59;
if ($department != null) {
i = $department.hashCode();
}
return i2 + i;
}
自己动手重写 equals() 和 hashCode() 方法,去掉 @EqualsAndHashCode 注解
// Department
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Department that = (Department) o;
return Objects.equals(id, that.id) &&
Objects.equals(deptName, that.deptName);
}
@Override
public int hashCode() {
return Objects.hash(id, deptName);
}
// Employee
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return Objects.equals(id, employee.id) &&
Objects.equals(empName, employee.empName) &&
Objects.equals(empJob, employee.empJob) &&
Objects.equals(deptId, employee.deptId);
}
@Override
public int hashCode() {
return Objects.hash(id, empName, empJob, deptId);
}
再次运行测试用例,测试通过
总结:慎用
@Data注解,使用@Getter,@Setter注解,需要时自己重写toString(),equals()以及hashCode()方法
审计 Auditing
一般数据库表在设计时都会添加 4 个审计字段,Spring Data Jpa 同样支持审计功能。Spring Data 提供了@CreatedBy,@LastModifiedBy,@CreatedDate,@LastModifiedDate 4 个注解来记录表中记录的创建及修改信息。
实体类
package com.example.springbootjpa.entity;
import lombok.Data;
import org.hibernate.annotations.GenericGenerator;
import org.springframework.data.annotation.CreatedBy;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.LastModifiedBy;
import org.springframework.data.annotation.LastModifiedDate;
import org.springframework.data.jpa.domain.support.AuditingEntityListener;
import javax.persistence.*;
import java.util.Date;
import java.util.Set;
@Entity
@EntityListeners(AuditingEntityListener.class)
@Table(name = "tb_user")
@Data
public class User {
@Id
@GenericGenerator(name = "idGenerator", strategy = "uuid")
@GeneratedValue(generator = "idGenerator")
private String id;
@Column(name = "username", unique = true, nullable = false, length = 64)
private String username;
@Column(name = "password", nullable = false, length = 64)
private String password;
@Column(name = "email", unique = true, length = 64)
private String email;
@ManyToMany(targetEntity = Role.class, cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinTable(name = "tb_user_role", joinColumns = {@JoinColumn(name = "user_id", referencedColumnName = "id")},
inverseJoinColumns = {@JoinColumn(name = "role_id", referencedColumnName = "id")})
private Set<Role> roles;
@CreatedDate
@Column(name = "created_date", updatable = false)
private Date createdDate;
@CreatedBy
@Column(name = "created_by", updatable = false, length = 64)
private String createdBy;
@LastModifiedDate
@Column(name = "updated_date")
private Date updatedDate;
@LastModifiedBy
@Column(name = "updated_by", length = 64)
private String updatedBy;
}
实体类上还添加了 @EntityListeners(AuditingEntityListener.class),而 AuditingEntityListener 是由 Spring Data Jpa 提供的
实现 AuditorAware 接口
光添加了 4 个审计注解还不够,得告诉程序到底是谁在创建和修改表记录
/src/main/java/com/example/springbootjpa/auditing/AuditorAwareImpl
package com.example.springbootjpa.auditing;
import org.springframework.data.domain.AuditorAware;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Component
public class AuditorAwareImpl implements AuditorAware<String> {
@Override
public Optional<String> getCurrentAuditor() {
return Optional.of("admin");
}
}
这里简单的返回了一个"admin"字符串来代表当前用户名
启用 Jpa 审计功能
在Spring Boot启动类上添加 @EnableJpaAuditing 注解用于启用 Jpa 的审计功能
package com.example.springbootjpa;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.jpa.repository.config.EnableJpaAuditing;
@SpringBootApplication
@EnableJpaAuditing
public class SpringBootJpaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootJpaApplication.class, args);
}
}
更多关于Jpa Specifications,Example查询请查阅官方文档