后端常见问题
[1] Batch update returned unexpected row count from update [0]; actual row count: 0; expected: 1
问题原理
该问题通常在使用 JPA 或 Hibernate 的 saveOrUpdate 或类似的方法时出现。
简单解释这个问题的原因就是:saveOrUpdate 或类似的方法要求实体的 ID 为 null 时才执行 SAVE 操作 (对应数据库的 Insert),如果 ID 不为 null,就默认数据库中已经存在该调数据,在这种情况下就会执行 UPDATE 操作 (对应数据库的 Update)。正常通过 saveOrUpdate 保存实体数据的时候是新增,但如果此时实体的 ID 不为 null,saveOrUpdate 保存实体数据时就会改为 UPDATE 操作,但是数据表中并不存在以 ID 值作为主键的数据,那么更新操作失败,所以出现异常。
Dante Cloud 出现此问题的原因
Dante Cloud 出现此问题,原理与上面所述的"问题原理"基本类似。
主要原因是服务在启动时,会扫描接口数据作为权限,汇总保存至 sys_authority 数据表中,由于增加的缓存的支持,所以在保存同时会向缓存中存储缓存数据。很多情况出现该问题,都是因为第一次部署不熟悉,要么发现操作步骤出错,要么发现配置错误等,在第一次表建好之后,清理了已有的表重新启动服务打算重新建。因为在第一次启动服务时,就会进行一次权限数据的汇总,缓存中就已经存在了数据。将数据表清理之后,再次启动服务,服务会首先读取缓存,发现缓存中有数据就认为是 UPDATE 操作,而此时数据库中并没有对应数据,所以导致跑错。
解决办法
发现服务运行出现 Batch update returned unexpected ... 错误,首先将所有服务停止,清理 Redis 中已经存储的缓存数据,再次启动服务即可。
[2] Failed to bind properties under 'spring.datasource.password' to java.lang.String
所有基础设施搭建完成、代码编译完成之后,再运行服务时,有时会遇到服务运行抛出Failed to bind properties under 'spring.datasource.password' to java.lang.String错误,导致无法运行的情况。出现这种问题的原因有很多,例举几种常见情况:
(1) Nacos 无法正常访问或配置不正确
因为服务相关的所有配置,绝大部分都是通过读取 Nacos 获得。如果 Nacos 无法正常访问,当然就会导致服务无法运行。因为很多 Spring Boot 或 Spring Cloud 组件的运行依赖于正确的配置信息。
Nacos 无法正常访问的情况就会有很多种,比如:
- Nacos 运行异常:连 Nacos 后台管理页面也无法打开,这种情况就需要检查 Nacos 的安装是否正确
- 网络不通:很多情况下会选择服务与 Nacos 不再同一台机器中,网络不通就会导致无法访问。
- 配置错误:工程根目录下的 pom.xml 中,需要对 Nacos 的访问地址进行配置,配置错误当然也无法访问。(需要注意的是 pom 文件中 Nacos 配置完或者修改后,要重新编译代码才能正常访问,具体原因参见多环境配置章节)
- Nacos Namespace 使用不正确:工程根目录下的 pom.xml 中,除了需要配置 Nacos 地址外,还有一项配置
<config.namespace>。如果在 Nacos 中,将本系统的配置导入到了某个命名空间中,那么就要在此处配置所使用命名空间的 ID;如果没有使用任何命名空间,那么该配置就留空。
提示
所以本系统一直强调,第一搭建环境还不了解本系统的情况下,建议一定要按照文档一步一步的进行操作。等运行成功之后,再结合自己的需求进行变更和修改。
不要上来就按照自己的方式进行变更或修改,改了以后发现出错,就来交流群里面用“一句话、一张图”的方式问问题。就算有人帮助解决问题,也对自己的修改“讳莫如深”,除了回答“不行”以外,多一个字都懒得说,这就是在浪费别人的时间。
(2) JDK 版本使用问题
目前大多数项目仍旧还是使用 JDK 1.8 版本。虽然 JDK 1.8 也已经发布多年,比较稳定问题也比较少,但是也不排除所使用 JDK 1.8 版本不同,而产生不可预知的甚至是“诡异的”问题。(JDK 本身也是由代码组成,既然是代码就有出现 BUG 的情况)
特别是 JDK 1.8 版本,本身就有点特殊。因为在 Oracle 官网中,只有 JDK 1.8 版本的 JDK 有特殊的版本罗列,如下图所示。也因此猜测肯定是因为有某些较大差异,无法兼容出来才特别出了不同的版本。
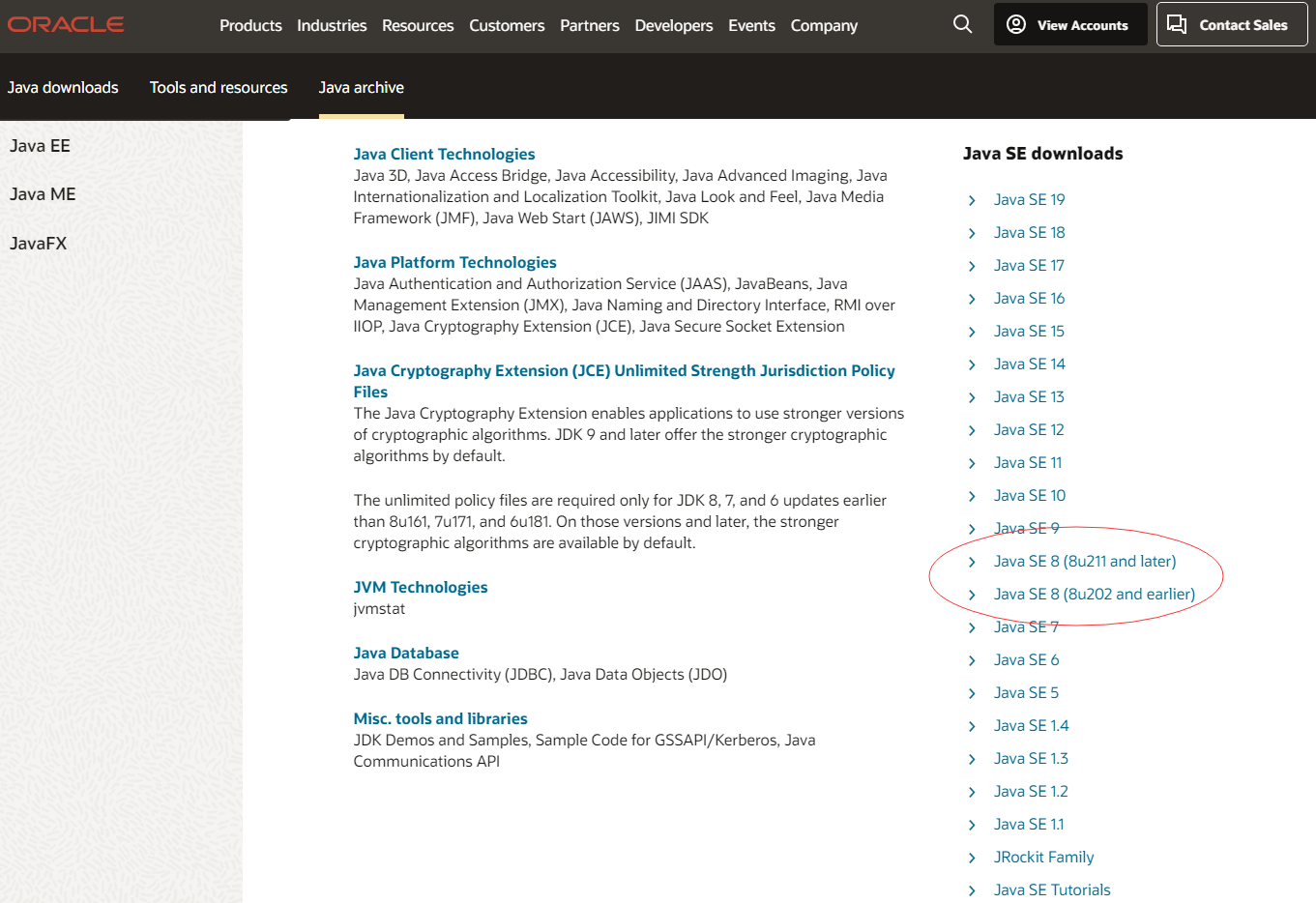
本项目就曾出现过,因为使用 JDK 版本的原因导致服务无法正常运行的问题。具体可以参见 Gitee ISSUE
说明
所以本项目建议使用最新版本的 JDK 1.8,(比如:1.8.0_3XX,本项目都是基于 1.8.0_3XX 开发,所以有问题也肯定被发现解决了)
就算不能使用 JDK 1.8 的最新版,也建议至少使用版本 > 1.8.0_211
[3]Redis 密码包含特殊字符无法连接
既然称之为特殊字符,大多都是特殊用途的符号。比如说 “@”,在很多连接协议中都是作为分隔符存在。在很多中间件或数据库之类的软件中,对于密码中包含的特殊字符也会有不同的要求。
Redis 连接密码除了极特别特殊字符外(具体是什么还是自己尝试吧),也是允许包含一些特殊字符的。
Dante Cloud 用户也曾遇到 Redis 密码中包含特殊字符,导致服务无法正常连接 Redis 而导致服务启动出错的问题。一下就是出错密码的示例:
mg3y9^3Wkp*g&ZBc.qM2正常情况下,在 Spring Boot 环境的配置文件中,指定 Redis 的密码配置,Spring Data Redis 也会进行一定的转义,保证密码可用。本系统无法使用该密码,并非是 Spring Boot 的转义没有生效,而是因为系统中还集成了 JetCache。JetCache 在使用 Lettuce 进行 Redis 连接时,采用的是 url 协议进行 Redis 连接。
url:
- redis://password@ip:port这就导致包含特殊字符的 Redis 密码无法正常连接 Redis。
而 JetCache 作者也表示,不打算支持特殊字符的转义。
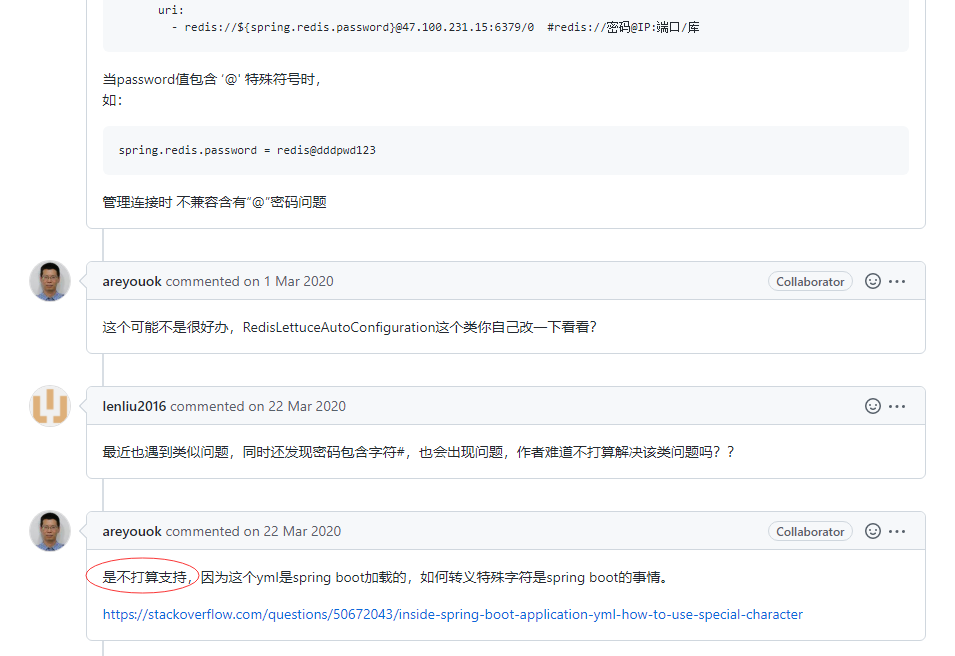
也尝试过对密码进行转义,但目前没有成功。如果你有什么好的解决办法,欢迎提 ISSUE 或 PR。
[4]能不能不用 Kafka(或消息队列)
为什么要用消息队列
消息队列是多系统集成的多种方式中,比较好的一种方式。既规避了 ETL 集成方式时效性差的问题,又规避了纯页面或者纯接口集成方式出发机制不理想的问题,而且将多系统集成的耦合性降到了最低。
微服务平台看似是一个完整的系统,本质还是多个系统(服务)间的整合及配合。因此,消息队列是必不可少的一个组成部分。
目前,就作者已知的或已了解过的开源微服务框架,还没有发现那个系统不用消息队列的。(不一定都是用 Kafka,但都是用了消息队列)
确实不想用怎么办
因为本系统没有使用最基础的 Kafka,而是集成了 spring-cloud-bus。而 spring-cloud-bus 又依赖于 spring-cloud-stream、spring-integration和 spring-kafka 等多种组件。这就导致无法简单的通过修改配置文件来彻底关闭 Kafka。
友情提示
spring-integration 是个神器的存在,只要你代码的上下文中包含 spring-cloud-stream 或 spring-kafka 等依赖,连 Swagger 都会主动去连接消息队列。
所以想要彻底不使用 Kafka (消息队列),只能通过去除依赖包的方法。
具体操作的步骤是:
- 在
dante-cloud-message包中,删除spring-cloud-starter-bus-kafka依赖。 - 把
dante-cloud-message包中涉及到 Kafka 相关引用的代码删除。 - 将
dante-cloud-bpmn-ability包中,@KafkaListener注解以及代码引用删除 - 重新编译代码运行。
警告
消息队列是本系统的核心组件,因目前关联的内容还不算特别多。非要剔除消息队列,可能导致部分功能的无法使用或者出现后续版本不兼容的情况。
所以请三思而后行!切记!
[5]为什么没有看到 Seata
文档中,有提到本系统集成了 Seata,问什么在代码中,连 Seata 的安装信息都没有看到。
这个问题的主要原因是:
- 当前开源版本基础的服务本身比较少,没有什么具体的、合适的场景必须用到
Seata。即使加上就是多装一个东西,最多些点 Demo 代码。 - 在这种情况下,强制加上
Seata只会增加本系统搭建资源成本、时间成本以及复杂程度。特别是学习使用本系统的朋友,各种能力程度和技能水平的都有,有些朋友搭建基本内容都有困难,多一项内容就更多了一份难度。 - 微服务框架本身涉及的内容就非常多,个人观点非必要、非必需的内容没有必要增加太多。确实需要时,集成一个
Seata也非常简单,真正能用起来的东西才是有价值的。就像做单体项目时,又有多少人真真正正的使用过“事务”?
提示
这里引用一篇个人认为比较好的介绍分布式事务文章的结论供参考:
上边简单介绍了 2PC、3PC、TCC、MQ、Seata 这五种分布式事务解决方案,还详细的实践了 Seata 中间件。但不管我们选哪一种方案,在项目中应用都要谨慎再谨慎,除特定的数据强一致性场景外,能不用尽量就不要用,因为无论它们性能如何优越,一旦项目套上分布式事务,整体效率会几倍的下降,在高并发情况下弊端尤为明显。